

Bu yazımızda rastgelelik ve karmaşıklık kavramlarını irdeleyeceğiz. Bu gönderinin amacı -sahip olduğumuz rastgelelik sezgisini bence en iyi şekilde biçimselleştiren- Kolmogorov karmaşıklığının ne olduğunu anlamak.
Kolmogorov karmaşıklığına ara sıra algoritmik entropi ya da algoritmik karmaşıklık denildiği de oluyor. Dr. Strangelove filmine gönderme yapan başlıktaki entropi kelimesi de buradan devşirme.
Rastgelelik nedir?
Eminim ki şu ana kadar denk geldiğiniz pek çok teizm-ateizm odaklı tartışmada “hiç böyle muntazam bir düzen rastgele oluşmuş olabilir mi” veya “buradaki mekanizmalar tesadüfen oluşmuş, şuradaki moleküller de rastgele dizilmiş” şeklinde sözler duymuşsunuzdur. Böyle lafların edildiği bir tartışmaya tekrar denk gelirseniz, sizden ricam şu basit soruyu sorun: Rastgelelik nedir ve rastgele olduğunu ya da olmadığını iddia ettiğimiz objelerin rastgeleliğini hangi ölçüte göre belirliyoruz?
Bu soruya yanıt alamamanız çok olası. Bunu “yukarıdakileri söyleyen insanlar çoğunlukla ne hakkında konuştuğunu bilmeyen şuursuzlar” demek için söylemiyorum. Tamam, dürüst olayım; aslında biraz bunu ima etmek için söylüyorum. Ama varmak istediğim nokta bu değil. Bu soru, eğer daha önce üzerine hiç düşünmediyseniz ya da araştırma yapmadıysanız, cevaplaması kolay bir soru değil. Bu blog gönderisinde bu soruyu cevaplayacağız!
Rastgelelik nedir sorusunu cevaplamaya çalışmadan önce neyin rastgele olup olmadığı hakkında konuşacağımızı belirlemeliyiz. Bu yazıda bir karakter dizisinin rastgeleliği için bir ölçüt bulmaya çalışacağız. Günlük hayatta karşılaştığımız çoğu şeyi -genel olarak bilgiyi- karakter dizilerine kodlayabildiğimiz için yapacağımız tanım bize oldukça geniş bir oyun alanı sağlayacak.
Şimdi bir alfabe sabitleyelim. Burada alfabe ile kastettiğim şey en az iki elemanı olan herhangi bir sonlu sembol kümesi. Bu sembol kümesini Türkçe alfabesi, 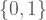

Rastgelelik sezgimizi biçimselleştirmek
Rastgelelik nedir sorusuna anlamlı bir şekilde cevap verebilmek istiyorsak rastgeleliğe ölçüt olarak sunacağımız şeylerin sahip olduğumuz rastgele sezgisinin özünü olabildiğince yakalaması lazım. Bu noktada küçük bir deney yapmak faydalı olabilir. Aşağıdaki karakter dizilerinden hangileri diğerlerine göre daha rastgeledir?
a.
b.
c.
d.
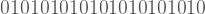
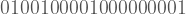

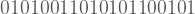
Sanırım herkes a dizisinin rastgele olmadığına katılacaktır. Biraz dikkatli bakınca b dizisinin rastgele olmadığı da görülebilir. Önce bir tane 

![[1,20]](https://s0.wp.com/latex.php?latex=%5B1%2C20%5D+&bg=ffffff&fg=4c4c4c&s=1&c=20201002)

Peki ya d dizisi de bir şeyleri temsil ediyorsa da biz farkına varamıyorsak? Olabilir. Doğruyu söylemek gerekirse d şıkkını tuşlara kafama göre basarak oluşturdum. Eğer illa d dizisini verecek bir kural arıyorsanız hemen bir tane kural üretebiliriz. Aynı c dizisinin bir ve yirmi arasındaki asal sayıları kodlaması gibi, d dizisi de şurada gördüğünüz onuncu derece polinomun gerçel köklerini kodluyor. Ama bu polinomun kendisi de yukarıdaki dizi kadar rastgele değil mi? Ne biçim katsayılar onlar öyle?! Hmm… Bence cevabı d olarak işaretlemeliyiz. Öte yandan ortada d dizisini veren bir kural da var.
Belki de soruyu değiştirmeliyiz. Yeni bir soru soralım. Yukarıdaki karakter dizilerini “rastgelelik derecelerine” göre sıralayınız.
Bu sefer cevabın a<b<c<d olması gerektiğinde sanırım hemfikiriz. Zira az önce gördüğümüz üzere sezgimiz bir şeyin rastgele olup olmadığına karar verirken sadece bir kural olup olmadığına değil, aynı zamanda o kuralın ne kadar karmaşık olduğuna da bakıyor. Bu küçük deney vasıtasıyla yapacağımız rastgelelik tanımına dair iki önemli kavram izole ettik: Kurallı olmak ve bu kuralın karmaşıklığı.
Kurallı olmak dediğimiz şey ne ola ki? Bir karakter dizisinin kurallı olması ne demek? Bu karakter dizisini üreten iyi tanımlanmış bir prosedür (bir algoritma) olması demek. Peki sahip olduğumuz algoritma sezgisini matematiksel olarak nasıl modelleyebiliriz?
Hesaplanabilirlik, algoritmalar ve Church-Turing tezi
Az önce sorduğumuz soru hakkında tuğla gibi kitaplar yazılmış bir soru. Bu yazının anlaşılabilmesi için tüm bunları bilmek bir önem teşkil etmediğinden dolayı sadece merak edenlerin araştırabilmesi adına anahtar kelimeleri vererek özet geçeceğim. İşin 1900 öncesine giden kısmını tamamen atlıyorum.
- Sene 1928. David Hilbert ünlü karar verme problemini ortaya atıyor. Soruyu cevaplayabilmek için haliyle insanların algoritma kavramını biçimselleştirmesi gerekiyor.
- Sene 1931. Kurt Gödel, ünlü eksiklik teoremini kanıtlarken ilkel özyinelemeli fonksiyonları kullanıyor. Gödel, tanımladığı ilkel özyinelemeli fonksiyonların algoritma sezgimizi tamamen yakalamadığının farkına varınca, Jacques Herbrand‘ın da katkılarıyla beraber, 1934’te genel özyinelemeli fonksiyonlar ortaya çıkıyor. Daha sonra Stephen Kleene olaya müdahil olacak ve bugün
–özyinelemeli fonksiyonlar dediğimiz fonksiyon sınıfını ortaya atacak, ki bu sınıftaki tam fonksiyonlar genel özyinelemeli fonksiyonlarla örtüşüyor.
- Tüm bunlar olurken 1936’da Alonzo Church efendi “
–calculus çok güzel, siz de gelsenize” diyerek yeni bir hesaplanabilirlik modeli ortaya atıyor.
- Sene 1936. Alan Turing doktora tez danışmanı olan Church’un modeline “Senin yapacağın
-indirgemesini şirinleyeyim” diye atarlandıktan sonra çığır açan makalesinde Turing makinelerini tanımlıyor. Aynı makalede karar verme problemini çözüyor ve Gödel’in teoreminin -daha farklı halinin- bir kanıtını veriyor. Bunları yaparken ortaya attığı evrensel Turing makinesi kavramı da on yıl içerisinde –John von Neumann‘ın da katkılarıyla- ilk bilgisayarlara dönüşmeye başlayacak.
- Sene hala 1936. Emil Post, Turing’den bağımsız olarak Turing’inkine çok benzer bir hesaplanabilirlik modeli ortaya atıyor.
(Not: Bu hikayedeki kişiler ve olaylar tamamen gerçek, diyaloglarsa hayalidir.)
Bu insanların hepsi sahip olduğumuz algoritma sezgisinin kendilerinin ortaya attıkları matematiksel modellere karşılık geldiğini söylüyorlar. Sonra ne oluyor? Hesaplanabilirlik kavramını biçimselleştiren tüm bu matematiksel modellerin birbirine denk olduğu ortaya çıkıyor. Yani birinde hesaplanabilir olan her şey diğerlerinde de hesaplanabilir.
Şimdi elimizdekilere bir bakalım. Tüm bu dehaların algoritma sezgimizi biçimselleştirmek için ortaya attığı farklı matematiksel modellerin hepsi birbirine denk. Bu matematiksel modellerin neden algoritma sezgimize karşılık gelmesi gerektiğine dair ikna edici sezgisel argümanlar da var. O zaman algoritma sezgimiz gerçekten de bu matematiksel modellerde ortaya atılan şeye denk geliyor olmalı!
Bu son cümledeki iddiayı alıp bir metatez haline getirdikten sonra da ismini Church-Turing tezi koyuyoruz. Tek cümlede özetlemek gerekirse: Algoritma demek Turing makinesi demek, Turing makinesi demek algoritma demek.
Kolmogorov karmaşıklığı nedir?
Bir önceki bölümde gördük ki, sahip olduğumuz algoritma sezgisini Turing makineleriyle biçimselleştirebiliyoruz. Dolayısıyla Turing makinelerini kullanarak bir karakter dizisinin kurallı olmasından bahsedebiliriz. Ancak her sonlu karakter dizisini çıktı olarak üretebilecek bir Turing makinesi bulunabilir. Öte yandan bizim için önemli olan sadece bir kuralın olması değil, basit bir kuralın olmasıydı. Bir karakter dizisini üreten kuralın ne kadar basit olduğunu pekala onu üreten Turing makinesinin ne kadar karmaşık olduğu üzerinden ölçebiliriz. Peki Turing makinelerinin karmaşıklıklarını nasıl ölçeceğiz?
Hatırlayın, Turing efendi evrensel Turing makinesi diye bir şey bulmuştu. Evrensel Turing makineleri, gerekli girdi verildiği zaman, diğer tüm Turing makinelerini taklit edebilen Turing makineleridir. O zaman, bir evrensel Turing makinesi sabitledikten sonra, bir karakter dizisinin rastgeleliğini onu üreten Turing makinesinin ilgili evrensel Turing makinesine göre kodunun uzunluğu olarak tanımlayabiliriz.
Farkındayım, son cümleyle ortalığı çok bulandırdım. Bu yazının [GM] serisinin bir parçası olarak geniş halk kitleleri için tasarlanmış olması gerekmiyor mu?

Bu noktada evrensel Turing makinelerini ve Kolmogorov karmaşıklığının matematiksel literatürdeki asıl tanımını bir kenara bırakacağım. Amacımız rastgeleliğin ne olduğunu anlamak, konuyla ilgili akademik makale yazmak değil. Bu yüzden, yazının geri kalanında anlatacağım her şeyi gerçek bir programlama dili üzerinde yapacağım.
Öte yandan, konuyla akademik olarak ilgilenmek isteyen ve aşağıda yapacağım tanımların matematiksel olarak doğru ifadelerini merak edenler olursa diye not düşeyim. Bu konuyu öğrenebileceğiniz temel kaynaklarından biri Algorithmic Randomness and Complexity kitabıdır.
Her neyse. Olabildiğince geniş bir halk kitlesine seslenebilmek adına içerisinde çalışacağımız programlama dilini C olarak seçiyorum. Bu seçimin bir sonucu olarak da bundan sonra karakter dizilerimizin sembollerinin içerisinden seçildiği alfabe sadece Hint-Arap rakamları kümesi değil, bu dilde çıktı olarak üretebileceğimiz tüm semboller kümesi olacak.
Aşağıda yapacağımız tanımların hepsini favori programlama dilinize kolayca genelleyebilirsiniz. Yapacağımız kanıtlar da sadece dilin çıktı üretmek ve döngü gibi temel fonksiyonlarını kullanacağından dolayı, ilgili kanıtların favori programlama dilinize aktarılmasını size egzersiz olarak bırakıyorum.
İşlerimizi kolaylaştırmak için programlama dilimizle ilgili -gerçek hayatta geçerli olmayan- birkaç varsayımlarda bulunacağız.
- Birinci olarak, programlama dilimizdeki programların kullanıcıdan girdi almadığını varsayacağız. Bu varsayım ilk başta saçma gözükebilir. Öte yandan, bir program+girdi ikilisi verildiğinde, ilgili girdiyi programın kaynak koduna hard-coded bir şekilde ekleyerek mevzubahis program+girdi ikilisiyle aynı işi gerçekleştiren ve kullanıcıdan girdi almayan başka bir program üretebiliriz. Demek ki programlarımızın girdi almadığını kabul etmemizde bir sakınca yok.
- İkinci olarak, bilgisayarımızın hafızasının sınırsız olduğunu varsayacağız. Matematik yapıyoruz şurada; evrendeki parçacık sayısı sınırlı diye teorem kanıtlamayacak değiliz ya?!
- Son olarak, programlama dilimizdeki değişkenlerin sınırsız büyüklükte değerler tutabildiğini varsayacağız. Lafın gelişi, int tipindeki bir değişken aldığımızda, bu değişken sınırsız büyüklükte tam sayıları taşma olmadan tutabilecek.
Şimdi yazının ana konusu olan Kolmogorov karmaşıklığını tanımlamaya hazırız.
Tanım: Bir 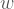

Üzerine biraz düşündüğünüzde, bu tanımın rastgelelik sezgimizle ne kadar örtüştüğünü görebilirsiniz. Bir diziyi üreten en kısa program (kural) ne kadar uzunsa (ne kadar karmaşıksa) o dizi algoritmik olarak o kadar karmaşıktır. Bir dizi algoritmik olarak ne kadar karmaşıksa, o kadar rastgeledir!
Bu noktada yaptığımız tanıma yapılabilecek bariz bir itiraz var. Eğer başka bir programlama dili kullanıyor olsaydık, karakter dizilerinin Kolmogorov karmaşıklıkları değişecekti. Bu durumda bir karakter dizisinin olası her programlama dili için ayrı bir Kolmogorov karmaşıklığı olacaktır. Bu eleştiride sonuna kadar haklısınız. Öte yandan, içerisinde çalıştığınız diller Turing-tam olduğu -yani bir evrensel Turing makinesini simüle edebildiği- sürece aşağıdaki teorem geçerli.
Teorem: 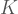
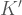

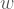
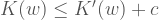
Yani bir programlama dilinden diğerine sıçradığımızda dizilerin Kolmogorov karmaşıklıkları en fazla -bu iki dile bağlı- bir sabit kadar değişebilir. Bunun anlamı da şu, karakter dizilerinin uzunlukları ve Kolmogorov karmaşıklıkları arasındaki ilişki, yeterince uzun karakter dizilerini göz önüne aldığımızda, içerisinde çalıştığımız programlama dilini değiştirmemizden fazla etkilenmeyecek. Dolayısıyla yaptığımız tanımın programlama diline bağımlılığı o kadar ciddi bir sorun değil.
Şimdi Kolmogorov karmaşıklığıyla ilgili basit bir gerçeği görelim . Her 
Teorem: Her 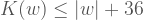
Kanıt: Bir
#include<stdio.h>
main(){printf(“w“);}
programı çıktı olarak 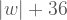
Aynen yazının başında yaptığımız deneyde d şıkkındaki karakter dizisini bir polinomun kökleri olarak hard-code ettiğimiz gibi, herhangi bir karakter dizisini o karakter dizinden en fazla 36 karakter daha uzun bir programla üretebiliyoruz. Dolayısıyla 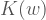
Mesela 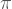
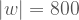
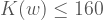
int a=10000,b,c=2800,d,e,f[2801],g;main(){for(;b-c;)f[b++]=a/5; for(;d=0,g=c*2;c-=14,printf(“%.4d”,e+d/a),e=d%a)for(b=c;d+=f[b]*a, f[b]=d%–g,d/=g–,–b;d*=b);}
Bu program şuradan alıntı. Bu karakter dizisini belki daha kısa bir programla üretmek de mümkündür. Bilmiyorum. Önemli olan zaten 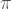
Buna karşın, mesela, 800 kere yazı-tura atarak sembolleri 0 ya da 1 olan bir karakter dizisi oluşturursam, bu durumda
Eğer az önce gerçekten de 800 kere yazı-tura atıp bir karakter dizisi üretmiş olsaydım, yazıp çizip üzerine düşündükten sonra
Kolmogorov karmaşıklığının hesaplanamazlığı
Yazının bu bölümünde hayatın acımasız gerçeklerinden biriyle karşılaşacağız:
Bu noktada üzerine basa basa vurgulama gereği duyuyorum. Hiçbir dizinin Kolmogorov karmaşıklığının hesaplanamayacağını söylemiyorum. Çeşitli spesifik dizilerin Kolmogorov karmaşıklıkları bulunabilir. Söylediğim şey, her dizinin Kolmogorov karmaşıklığını hesaplayacak bir algoritma olmadığı. Bunun kanıtını az sonra hep birlikte göreceğiz.
Kanıta geçmeden önce Bertrand Russell‘ın kütüphaneci G. G. Berry’ye atfettiği Berry paradoksundan bahsetmek istiyorum. Şu cümleye bakalım.
On iki kelimeden daha az kelimeyle tanımlanamayan en küçük doğal sayı.
Dilimizde sonlu tane kelime olduğuna göre en fazla on bir kelimeyle tanımlanabilen sonlu tane doğal sayı vardır. Bu durumda, sonsuz tane doğal sayı olduğuna göre, on iki kelimeden daha az kelimeyle tanımlanamayan doğal sayılar olmak zorunda. Dolayısıyla bunların en küçüğü de vardır. Öte yandan bu doğal sayıyı yukarıdaki ifadeyi kullanarak on bir kelime ile tanımladık. Çelişki.
Peki ortadaki sıkıntının kaynağı ne? Ortadaki sıkıntının kaynağı “tanımlanamayan” kelimesindeki belirsizlik. Zira bu kelimeyi kullanarak -üstü kapalı bir biçimde- dilimizdeki ifadelerin her birinin bir doğal sayı tanımlayıp tanımlamadığına karar verebileceğimizi varsayıyoruz. Öte yandan bu doğru değil. Mesela şu ifadeye bakalım.
Eğer ‘Bu cümle yanlıştır.’ cümlesi doğruysa birden büyük en küçük doğal sayı, değilse birden küçük en büyük doğal sayı
Bu ifade hangi doğal sayıyı tanımlıyor, iki sayısını mı sıfır sayısını mı? Bu ifade bir doğal sayı tanımlamıyor zira bu ifadenin tanımladığı doğal sayının ne olduğuna karar vermeye çalıştığımızda yalancı paradoksu suratımıza bir tokat gibi çarpıyor.
Şimdi Kolmogorov karmaşıklığının hesaplanamazlığının kanıtına geçebiliriz. Kanıtın ana fikri Berry paradoksunu taklit etmek olacak. Eğer Kolmogorov karmaşıklığı hesaplanabiliyor olsaydı, bu durumda Berry paradoksuna benzer bir çelişki kanıtlayabileceğimizi göreceğiz.
Teorem: Öyle bir program yoktur ki kendisine girdi olarak verilen her
Kanıt: Kanıtı olmayana ergi yöntemi ile yapacağız. Varsayalım ki Kolmogorov karmaşıklığını hesaplayan bir program yazabiliyoruz. Bu durumda, bu programı kullanarak öyle bir kolmogorov() fonksiyonu yazabiliriz ki bu fonksiyon kendisine verilen her tam sayı i değeri için alfabetik olarak i. sıradaki karakter dizisinin Kolmogorov karmaşıklığını döner. Şimdi şu kod parçasına bakalım.
#include<stdio.h>
[Burada kolmogorov() fonksiyonu olacak]
main()
{
int i;
for(i=0;;i++) if(kolmogorov(i)>k) {printf(“%d”,i); break;}
}
Burada k dediğimiz şey kaynak kodun içerisine elle girilmiş bir doğal sayı olacak. Hangi k değerinin kullanılması gerektiğini az sonra göreceğiz.
Bu programın ne yaptığı açık olmalı. Bir döngü vasıtasıyla i=0’dan itibaren alfabetik olarak i. sıradaki karakter dizisinin Kolmogorov karmaşıklığını hesaplıyor, eğer bu değer programa girilen k değerinden büyükse çıktı olarak bu karakter dizisini üretip duruyor. Yani bu program bize Kolmogorov karmaşıklığı k sayısından büyük olan alfabetik olarak ilk karakter dizisini veriyor.
Bu kaynak kodun k değerinin yazıldığı yer hariç uzunluğuna 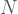
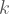
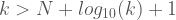
olur. Şimdi bu eşitsizliği sağlayan bir
Kolmogorov karmaşıklığı 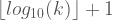
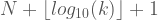
Ancak biliyoruz ki 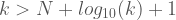


Görüldüğü üzere Kolmogorov karmaşıklığını algoritmik yöntemlerle hesaplayamıyoruz. Aksi takdirde Kolmogorov karmaşıklığını hesaplayan algoritmadan bu algoritmanın kendi uzunluğundan daha büyük Kolmogorov karmaşıklığına sahip bir karakter dizisini hesaplamasını isteyerek çelişki yaratabilirdik. Bu durumda da evren birdenbire yok olurdu!
Aslında yukarıda kanıtladığımızdan çok daha fazlası doğru. Kolmogorov karmaşıklığı kavramını velet yaşında kendi başına keşfedip, bunu her kitabında üstüne basarak vurgulayan yedi cihanın pek egomanyak matematikçilerinden Gregory Chaitin‘in konuyla ilgili bir eksiklik teoremi var.
Bu teorem kabaca şunu söylüyor. Belirli özellikleri sağlayan bir belitsel sistem aldığımızda öyle bir 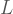

Yazının bir sonraki bölümüne geçmeden önce Kolmogorov karmaşıklığının hesaplanamazlığını kullanarak durma probleminin çözümsüzlüğünü de kanıtlamayı planlıyordum ama zaten gereğinden fazla uzayan bu yazıyı bir an önce bitirmek adına bu kanıtın sadece taslağını verip bırakacağım.
Diyelim ki öyle bir 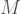

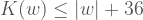
Algoritmik rastgelelik
Bu yazıdaki ana amacımız rastgelelik sezgimizle örtüşen matematiksel bir tanım bularak şeylerin ne kadar rastgele olduğuna karar vermekti. Kolmogorov karmaşıklığının ne olduğunu öğrendiğimize göre bu kavramı kullanarak bir rastgelelik tanımı yapabiliriz.
Bir 
Peki algoritmik olarak rastgele diziler var mıdır? Belirli bir uzunluktaki olası tüm karakter dizilerinin sayısını ve olası tüm kaynak kodların sayısını karşılaştırarak algoritmik olarak rastgele dizilerin var olması gerektiğini kolayca kanıtlayabilirsiniz. Okuyucuya egzersiz olsun bu.
Yazıyı noktalarken küçük birkaç not düşeyim. Yukarıdaki tanım altında kısa karakter dizilerinin çoğunun algoritmik olarak rastgele olduğunu göreceksiniz. Lafın gelişi, 01010101 dizisini üretmek için de 71214527 dizisini üretmek için de en kısa yol bu karakter dizilerini kaynak koda ekleyerek bastırmak. Biz bu dizilere baktığımızda 01010101 dizisinde 71214527 olmayan bariz bir kural görüyoruz. Öte yandan bu kuralı algoritmik olarak ifade etmek -dört kere dönen bir döngü yaratmak ve döngünün her dönüşünde 01 dizisini bastırmak- dizinin kendisini kaynak koda eklemekten daha pahalıya mal olacağı için, birinci dizide bariz bir kuralın olması onu ikinci diziden daha az rastgele yapmayacak.
Dolayısıyla, yaptığımız algoritmik rastgelelik tanımı kısa karakter dizilerinde -eğer gözlemlediğimiz kuralı algoritmik olarak ifade etmek en az dizinin kendisi kadar bilgi gerektiriyorsa- her zaman umduğumuz gibi sonuç vermeyebilir. Bununla birlikte, ilgilendiğimiz karakter dizilerinin uzunlukları arttıkça sezgisel olarak beklediğimiz şeye yakın sonuçlar alacağız.
Son olarak da Kolmogorov karmaşıklığını kullanarak sonsuz karakter dizileri için algoritmik olarak rastgeleliği tanımlamanın mümkün olduğunu belirteyim.
Not: Bu yazı Can Numan müstear ismiyle yayınlanmış olup Taner Beyter tarafından sitemize uyarlanmıştır.









